计算机视觉-Structure from Motion (SFM)
深入解析运动恢复结构 (SFM) 算法,探讨相机标定与三维点云重建原理
Structure from Motion
| calibration | triangulation | motion | |
|---|---|---|---|
| 输入 | Point pairs from 3D to 2D | camera parameters, point pairs from 2D to 2D | point pairs from 2D to 2D |
| 输出 | camera parameters | 3D points | 3D points and camera parameters |
The Ambiguity of Structure from Motion
SFM 并不是一个唯一解的问题,存在多种解的可能性。假设我们有一个解 $(P, X)$ 满足投影关系:
\[PX = x \Rightarrow P H^{-1} H X = x\]可见我们只要调整 H 变换,可以得到不同的解 $(P H^{-1}, H X)$。根据矩阵 $H$ 的不同性质,我们可以将这种模糊性分为三种类型:
Projective Ambiguity
Affine Ambiguity
Similar Ambiguity
Affine Structure from Motion
基于基本的相机模型,我们介绍经典的 SFM 方法——Affine Structure from Motion。该方法假设相机采用仿射投影模型,并且通过多张图像中的对应点来恢复三维结构和相机运动。
首先最为关键的,也就上面我们提到了,如何解决奇异性问题,我们采用仿射相机模型(Affine Camera Model),这种模型简化了投影过程,假设投影线是平行的,从而避免了透视畸变带来的复杂性。
我们知道 3Dto2D 可以分为两种情况:正交投影 和 仿射投影。
正交投影 假设相机远离物体,投影线与图像平面垂直,这种情况下投影矩阵可以表示为:
\[P = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}\]仿射投影 则考虑深度远近信息,投影矩阵可以表示为:
\[P = \begin{bmatrix} f & 0 & 0 & 0 \\ 0 & f & 0 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}\]而在 Affine Camera 中,我们采用简化的正交投影模型,加上相机本身的参数矩阵,我们就得到了简化相机模型:
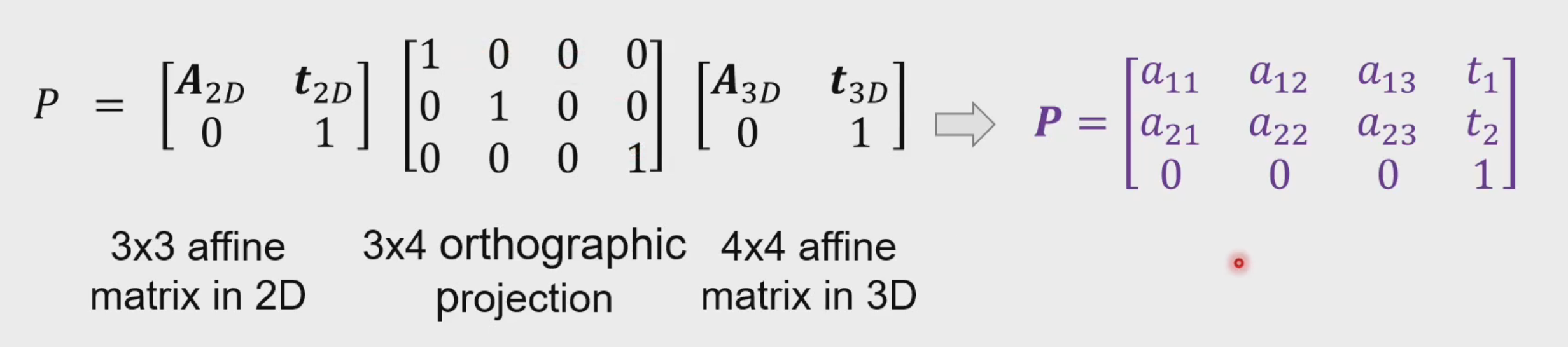
- 其中 $ 3\times 3 $ affine matrix 和 $ 4 \times 4 $ affine matrix 分别表示在 3D 和 2D 空间中的平移和旋转等基础变换,而中间使用正交投影矩阵进行投影。可以看到 P 的最后一行是 $ [0,0,0,1] $,这就保证了投影线是平行的,同时减少了 P 的自由度,也就消除了一部分奇异性。同时 A 的正交性约束也进一步减少了自由度。
接下来我们介绍如何通过多张图像中的对应点来恢复三维结构和相机运动。假设我们有 $m$ 张图像,每张图像中有 $n$ 个对应点,我们列出投影关系:
\[x_{ij} = P_i X_j + t_i \quad i=1,2,\ldots,m \quad j=1,2,\ldots,n\]但是这里面依然有奇异性问题,如果我们对 P 乘上仿射矩阵(最后一行是 0001) H 的逆,对 X 乘上 H,同样满足投影关系,也就是还有 12 个奇异性:
\[x_{ij} = P_i H^{-1} H X_j + t_i\]接着我们分析一下自由度,考虑系统方程求解需要的条件,n 个 P 矩阵与 t, m 个 X 矩阵和仿射矩阵的 12 个奇异性一共有:
\[\text{自由度} = m \cdot 8 + n \cdot 3 - 12\]而已知的投影点有:
\[\text{已知量} = m \cdot n \cdot 2\]所以我们需要满足:
\[m \cdot n \cdot 2 \ge m \cdot 8 + n \cdot 3 - 12\]T 看起来很别扭不是吗?我们可以通过中心化(centering)来简化问题。也就是将所有点的质心移动到原点,这样我们就可以消除 t 的影响,从而减少自由度:
\[\hat{x_{ij}} = x_{ij} - \sum_{j=1}^{n} x_{ij} / n = P_i (X_j - \sum_{j=1}^{n} X_j / n) = P_i \hat{X_j} = P_i X_j\]这里只需要人手动中心化 2D 的已知坐标,3D 坐标我们本来就是待求的,可以直接将质心设为原点(也就是最后一步去掉 hat 的原因)。这样我们就消除了 t 的影响,自由度变为:
\[\text{自由度} = m \cdot 8 + n \cdot 3 - 12 - 3\cdot m = m \cdot 5 + n \cdot 3 - 12\]对系统分析后我们得到了最终方程,接着展开矩阵形式,看一看怎么求解:
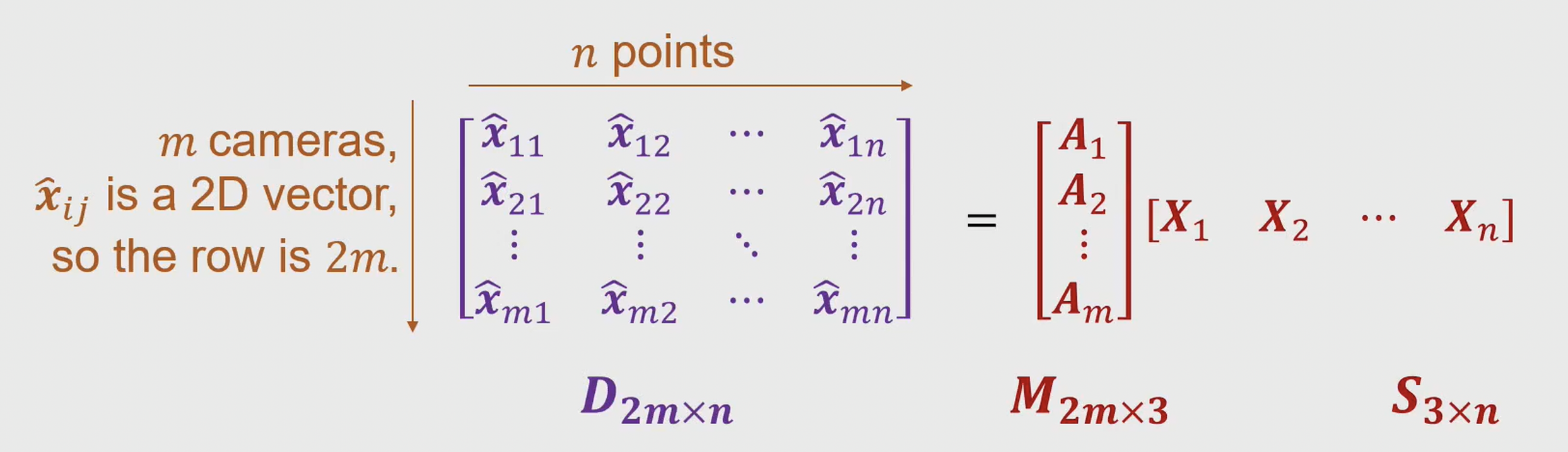
我们发现 M 和 S 的形状分别是 $2m \times 3$ 和 $3 \times n$ 的矩阵,而 D 是 $2m \times n$ 的矩阵。在线性代数中,我们知道一个矩阵的秩(rank)是其线性无关行或列的最大数量。对于矩阵 D 来说,由于它是由矩阵 M 和 S 的乘积得到的,因此 D 的秩受到 M 和 S 秩的限制。具体来说,矩阵 D 的秩不能超过矩阵 M 和 S 中较小的那个的秩。因此,我们可以得出结论:
\[\text{rank}(D) \leq \min(\text{rank}(M), \text{rank}(S)) \leq 3\]这意味着矩阵 D 的秩最多为 3。从一个大矩阵分解为两个小矩阵从而实现方程求解是一个老生常谈的话题,我们可以使用奇异值分解(Singular Value Decomposition, SVD)来实现这个分解过程。通过 SVD,我们可以将矩阵 D 分解为三个矩阵的乘积:
\[D = U \Sigma V^T\]其中,U 和 V 是正交矩阵,Σ 是一个对角矩阵,其对角线上的元素称为奇异值。因为存在误差,Σ 不一定只有前三个奇异值非零,通过截断 Σ,只保留前三个最大的奇异值,来近似地重构矩阵 D:
\[D \approx U_3 \Sigma_3 V_3^T\]这样,我们就可以通过 SVD 分解得到矩阵 M 和 S 的估计值:
\[M = U_3 \Sigma_3^{1/2} \qquad S = \Sigma_3^{1/2} V_3^T\]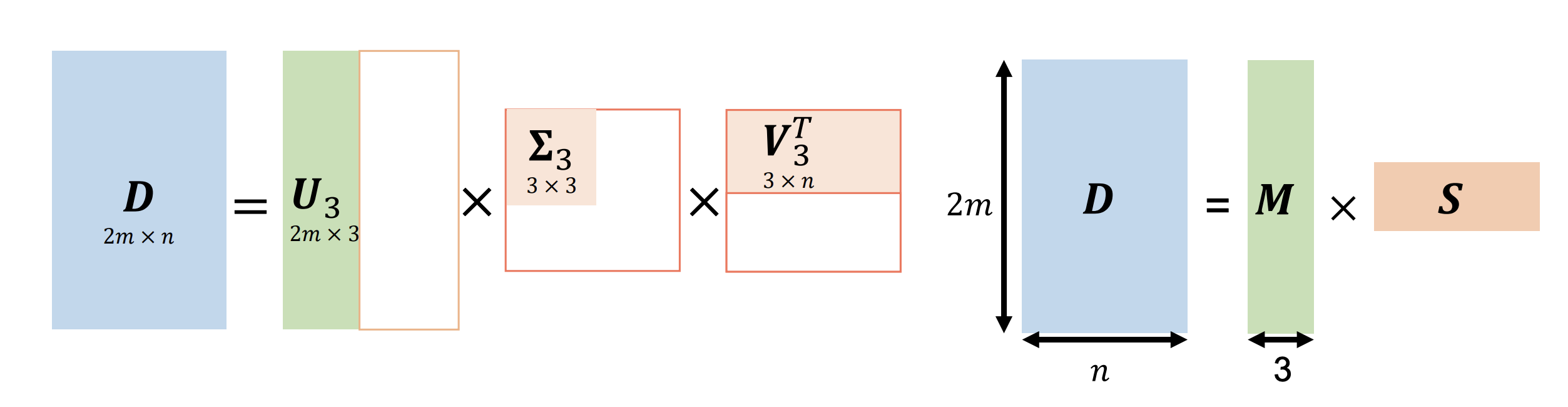
但是这里面依然有奇异性问题,如果我们对 M 乘上任意仿射矩阵 H 的逆,对 S 乘上 H,同样满足投影关系,也就是还有 9 个奇异性,这时我们用上之前正交性的约束来消除奇异性,我们的 A 必须满足正交性,那么乘上 H 后也必须满足正交性:
\[(A_iH)(A_iH)^T = A_i H H^T A_i^T = I\]这个约束是很强的,但是并非线性不好解,我们先定 $N = HH^T$
\[A_i N A_i^T = I\]这是一个线性方程,我们可以解出 N,然后通过 Cholesky 分解(Cholesky Decomposition)来求解 H:
\[N = HH^T\]Dealing with Missing Data
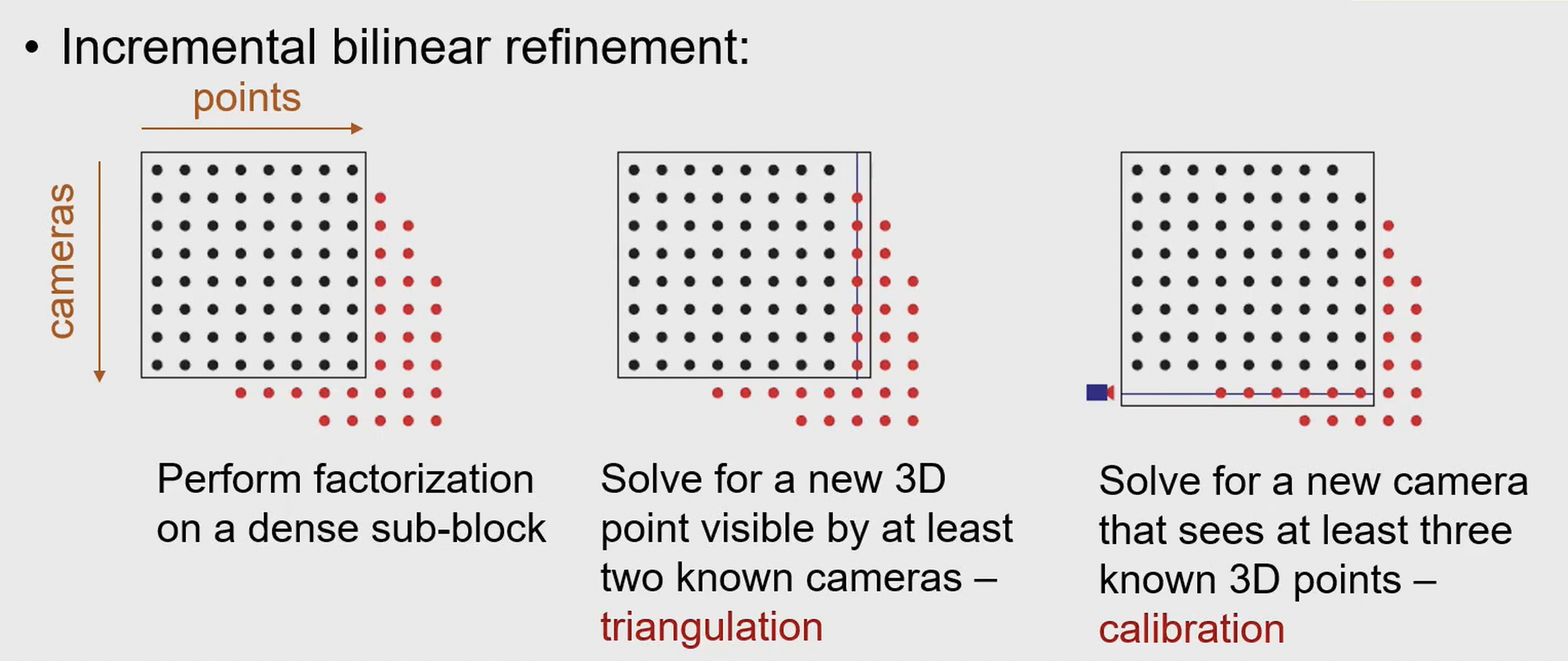
在实际应用中,我们经常会遇到数据缺失的情况,比如某些图像中的某些点没有被正确匹配到对应的三维点。为了处理这些缺失的数据,我们可以采用下面这个方法,寻找一个最佳的稠密矩阵为起点,然后通过迭代的方法来完善缺失的数据。
Projection Structure from Motion
从正交映射的仿射矩阵改为透视投影矩阵,我们就得到了Projection Structure from Motion。这种方法更符合实际的相机模型,可以更准确地恢复三维结构和相机运动。但随之而来的就是更多的自由度和更复杂的计算过程。
Bundle Adjustment
系统通常会有误差,我们可以通过Bundle Adjustment 来优化结果。Bundle Adjustment 是一种非线性优化技术,旨在同时优化相机参数和三维点的位置,以最小化投影误差。具体来说,我们定义一个目标函数,表示所有图像中投影点与实际观测点之间的误差平方和:
\[J = \sum_{i=1}^{m} \sum_{j=1}^{n} w_{ij}\| x_{ij} - \hat{x}_{ij} \|^2\]- $ \hat{x_{ij}} = proj(P_{i}X_{j}) $, $ w_{ij} $ 表示观测权重(如果点 $ j $ 在图像 $ i $ 中可见,则 $ w_{ij}=1 $,否则为 0)。
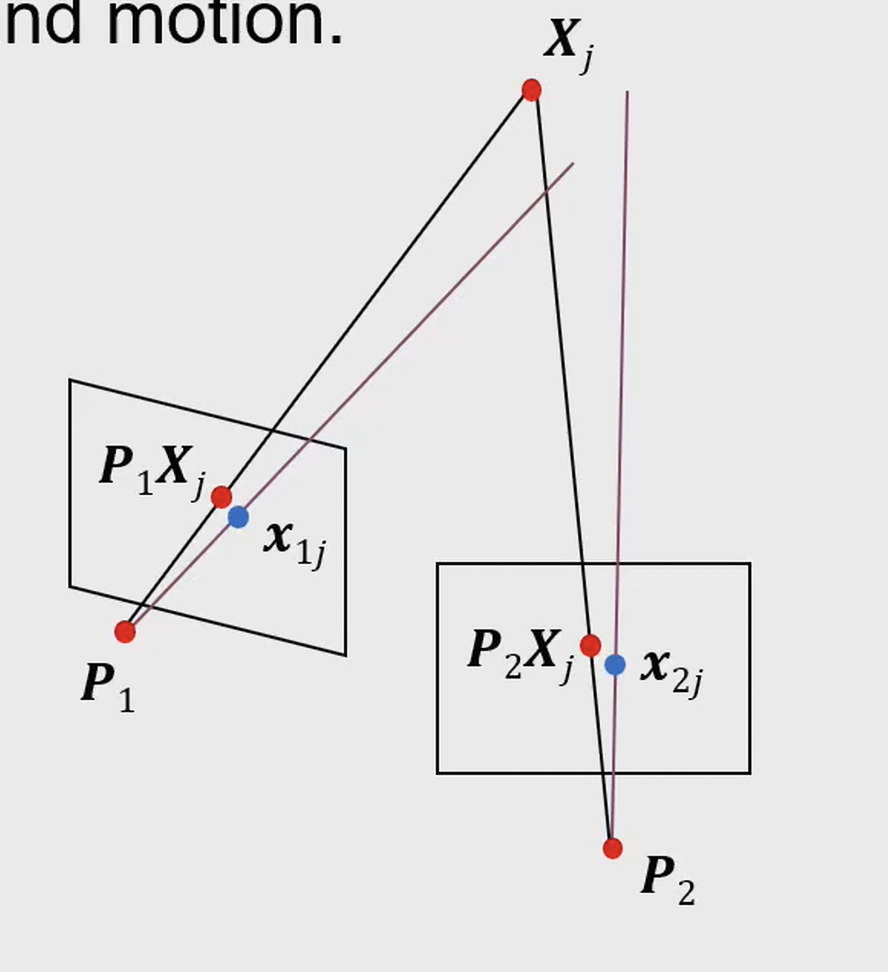
Self-Calibration
如果相机内参未知,我们可以通过Self-Calibration 来估计相机内参。Self-Calibration 利用多张图像中的对应点,通过分析投影矩阵的性质,来恢复相机的内参矩阵。
Incremental Structure from Motion
类似于解决 Missing Data 的思路,我们可以通过增量式的方法来逐步构建三维结构和相机运动。首先从少量的图像开始,恢复初始的三维结构和相机参数,然后逐步加入新的图像,分别使用Triangulation 来恢复新增对应点的三维结构,使用Calibration来恢复新增图像的相机参数。
但是增量式的方法容易受到误差的累积影响,因此在每次加入新的图像后,我们通常会使用 Bundle Adjustment 来优化整个系统的参数,从而减少误差的影响。
Dealing with Repetition and symmetry
Conclusion
我们到现在基本实现了从多个 2D 图像重建 3D 结构的流程,首先利用 Feature Detection 识别 2D 特征,随后通过 Feature Matching 获得多张图像中的对应点,接着使用 Epipolar Geometry 和 RANSAC 计算 Fundamental Matrix,然后利用上面的 Incremental Structure from Motion 方法恢复三维结构和相机运动,最后通过 Bundle Adjustment 优化结果。这个流程是 3D 视觉的核心基础,后续的多视图几何、立体视觉等内容均基于此进行扩展。
Enjoy Reading This Article?
Here are some more articles you might like to read next: