计算机视觉-Multi-View Stereo (MVS)
多视角立体视觉技术,从校准图片构建稠密 3D 模型
Multi-View Stereo
输入经过 Calibrated 的多张图片(保证完整性),输出稠密的 3D 重建模型(Voxel、Mesh、Points Cloud)
Basic Idea:图像间的密集对应关系
Silhouette-based MVS
Visual Hull
Plane-Sweeping Stereo
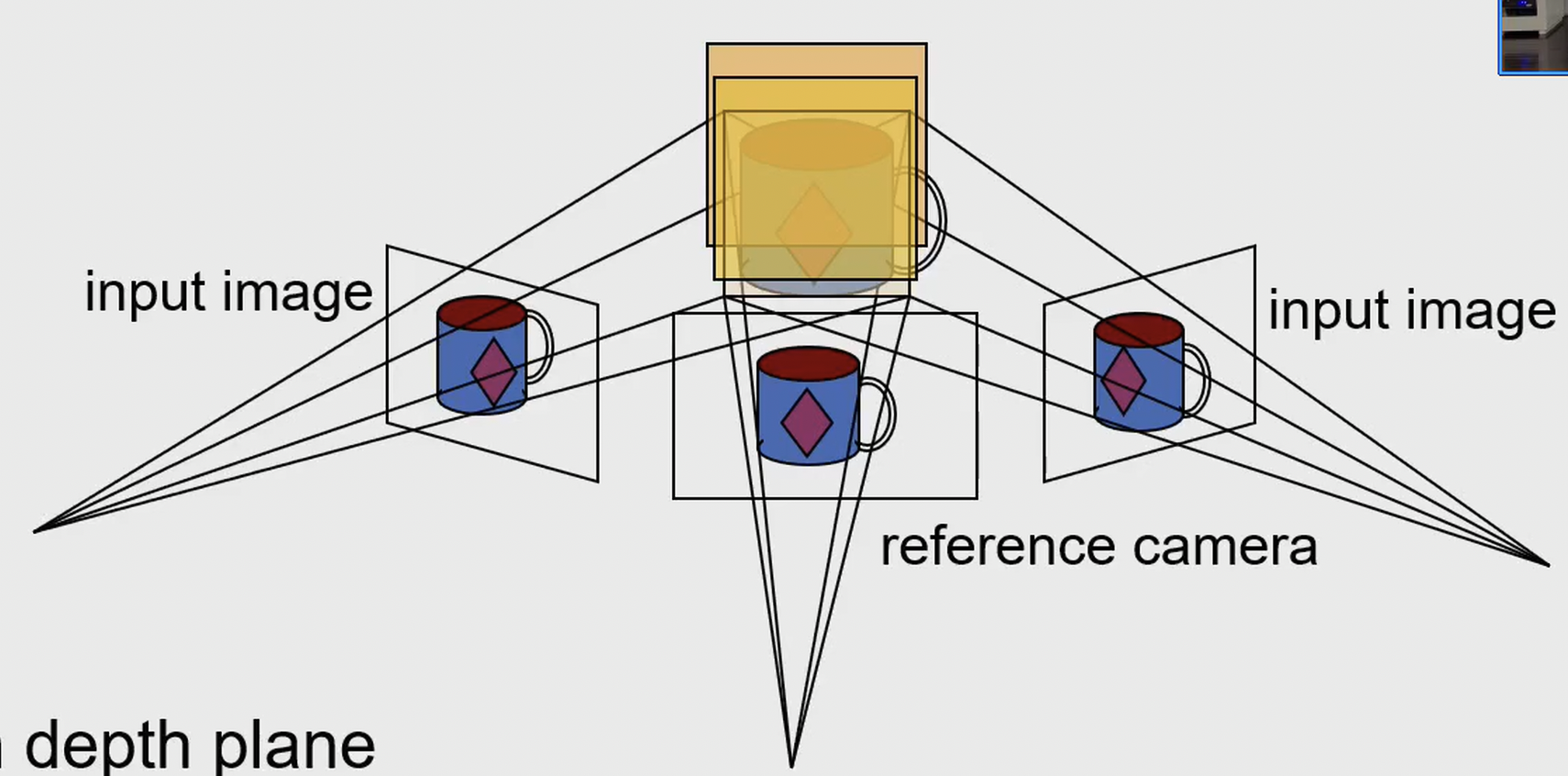
Depth Map based MVS
通过轮廓线或者平面扫面,我们通常只能得到一个物体的结构,对于全局的结构(比如 3D 场景)很难进行恢复,因此我们需要更精细的深度图进行补全。
我们已知怎么从两张图获得深度图,因此我们两两取对计算深度图,随后融合深度图。不过这时的两两计算应该减少局部约束比如平滑去噪,详情见下图:
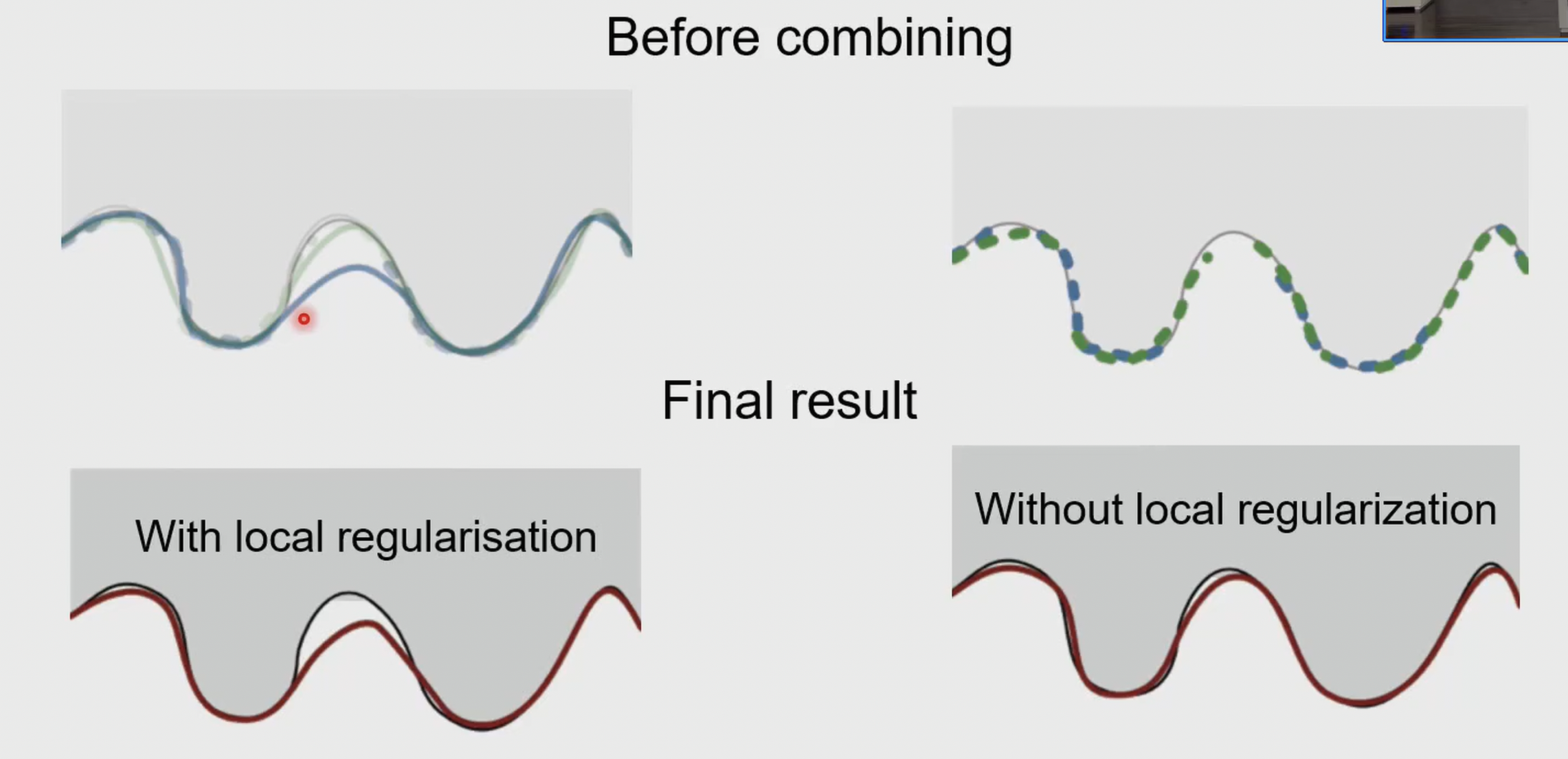
- 当两张图的时候因为视角限制,无法看到部分区域会出现“漏洞”,因此我们进行平滑处理,但是如果我们有多张图,我们可以通过多张图的深度信息进行补全,从而减少平滑处理带来的误差,此时如果提前平滑会丢失一些细节,因此我们应该先计算深度图,随后再进行融合和平滑处理
Patch-based MVS
之前在 [[L8 Two-View Stereo]] 中,我们探索过逐像素匹配的误差行,而之前Depth Map方法比较依赖像素级别的匹配,所以该方法通过小块区域进行匹配,从而增加鲁棒性。
What is Patch?
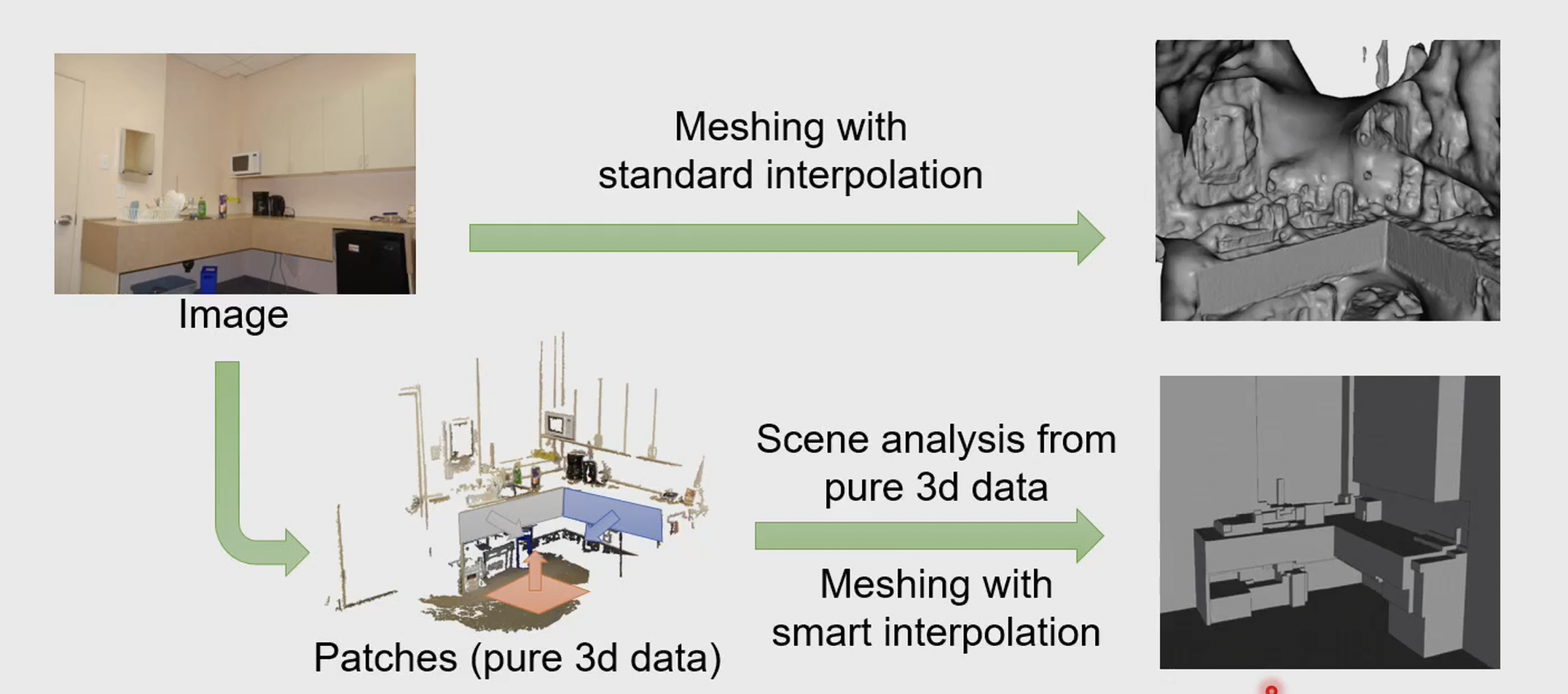
Patch 是图像中的一个小区域,通常是一个矩形或正方形区域,包含多个像素点(类似于卷积),而且同时包含了该区域面的法向量信息。一方面 patch 不至于过大,我们可以用平面 patch 拟合整体曲面,而平面方便操作计算;另一方面 Patch 又包含了范围信息,对像素的连续性加了较强约束。下图展示了从标准 3D 信息中进行 Patch 重建和点重建的区别:
Patch Similarity
Patch-based MVS 方法通过比较不同图像中对应 Patch 的相似性来估计深度信息。那么我们如何定义 Patch 之间的相似性呢?
我们将 N (I, J, p) 定义为:在图像 I 和 J 中,Patch p 的一致性函数。我们首先将 3DPatch 投影到两个图像上,随后计算两个 Patch 之间的颜色差异,定义为:
\[N (I, J, p) = \frac{\sum(I_{xy}- \bar{I_{xy})\cdot (J_{xy}- \bar{J_{xy}})}}{\sqrt{\sum(I_{xy}- \bar{I_{xy}})^2 \sum(J_{xy}- \bar{J_{xy}})^2}}\]而 $N(p)$ 为所有可见图像对 $V(p) = {I_1,…,I_n}$ 之间的一致性函数的平均值:
\[N(p) = \frac{\sum_{i = 1}^{n} \sum_{j = i+1}^{n} N(I_i, I_j, p)}{n(n-1)}\]而 Patch 是一个关于位置、法向量和课件图像的函数,我们可以通过优化位置和法向量来最大化一致性函数,从而获得最佳的 Patch。具体优化过程比较复杂,大体思想是 coodinate descent,我们每次固定其他变量,优化一个变量,迭代进行直到收敛。
但更新 V (p) 也很重要,因为随着 Patch 位置和法向量的变化,Patch 可见的图像对也会变化,因此我们需要不断更新 V (p),从而保证一致性函数的正确性。这个函数不可微分,因此我们通过暴力搜索的方式进行更新。首先计算每张图对其他图的一致性函数之和,选择第一个图像作为参考图像,随后选择与参考图像一致性函数最大的图像作为第二个图像,依此类推,直到一致性函数小于某个阈值为止。
Procedure
我们首先通过几张图片进行特征点匹配,获得初始的 sparse 3D points,然后我们通过这些 sparse 3D points 进行 Patch 初始化,随后进行 Patch 优化。
随后我们对 Patch 进行拓展和过滤:
- Patch Extension:我们通过初始 Patch 进行拓展,生成新的 Patch,随后进行优化。具体来说我们选择一个已经优化的 Patch,检查其映射后的邻域,如果邻域内没有 Patch,我们就生成一个新的 Patch(初始化时复制原已优化 Patch),随后进行优化。直到我们无法生成新的 Patch 为止。
- Patch Filtering:我们通过一致性函数对 Patch 进行过滤,去除那些一致性较差的 Patch,从而提高最终重建的质量。还有遮挡的 Patch 也会被去除。
Neural Radiant Fields (NeRF)
NeRF 是一种基于神经网络的 3D 重建方法,通过训练一个神经网络来表示场景的体积密度和颜色信息,从而实现高质量的 3D 重建和渲染。
首先 NeRF 是以光线为基础的,我们通过相机参数和像素位置生成光线,随后通过神经网络预测光线上的体积密度和颜色信息,最后通过体积渲染技术合成图像。具体来说,我们设 s 是光线上的某个位置,一束光在该位置的颜色为 $I(s)$,初始颜色为 $I(0)$,然后空间在某一位置的“密度”为 $\tau(s)$ 那么我们有以下公式表示光线经过一段路径抵达 s 产生的衰减(假设这段位移很小,密度相同):
\[\frac{dI(s)}{ds} = -\tau(s) I(s)\]这是一阶线性微分方程,我们可以通过积分得到光线终点的颜色:
\[I(s) = I(0) \exp(-\int_{0}^{s} \tau(t) dt)\]这里我们考虑物理意义,$\exp(-\int_{0}^{s} \tau(t) dt)$ 可以表示光线在路径上由于介质吸收而衰减的比例。我们表示不透明度为 $\alpha(s) = 1 -\exp(-\int_{0}^{s} \tau(t) dt)$,那么我们有:
\[I(s) = I(0) (1 - \alpha(s))\]这样我们获得了在通过一段已知密度介质中的光线颜色。随后我们将整段光线分割成多个小段,我们可以获得最后的颜色为:
\[I(L) = \sum_{i=1}^{N} \prod_{j=1}^{i-1} (1 - \alpha_j) c_i \alpha_i\]- 理解为:每一小段的颜色 $ c_i $ 乘以该段的不透明度 $ \alpha_i $,再乘以前面所有段的透明度 $ \prod_{j=1}^{i-1} (1 - \alpha_i) $,最后对所有小段进行求和。
随后我们通过神经网络来预测密度 $\tau(s)$ 和颜色 $c(s)$ ,具体来说,我们将位置 s 和视角方向 d 作为输入,经过一个多层感知机 (MLP) 网络,输出密度:
\[(\tau(s),c(s)) = MLP(s, d)\]Gaussian Splatting
Gaussian Splatting 是一种基于高斯分布的 3D 重建方法,通过在空间中放置多个高斯分布来表示场景的体积密度和颜色信息,从而实现高质量的 3D 重建和渲染。
Enjoy Reading This Article?
Here are some more articles you might like to read next: